
Geometry
Line Features and Hybrid Methods
Line features for 3D reconstruction and visual localization.



Geometry
Privacy Preservance
Privacy preserving techniques in mapping, localization and features.


Geometry
General Robust Estimation
We address the problem of robust estimation from visual data and additional priors.
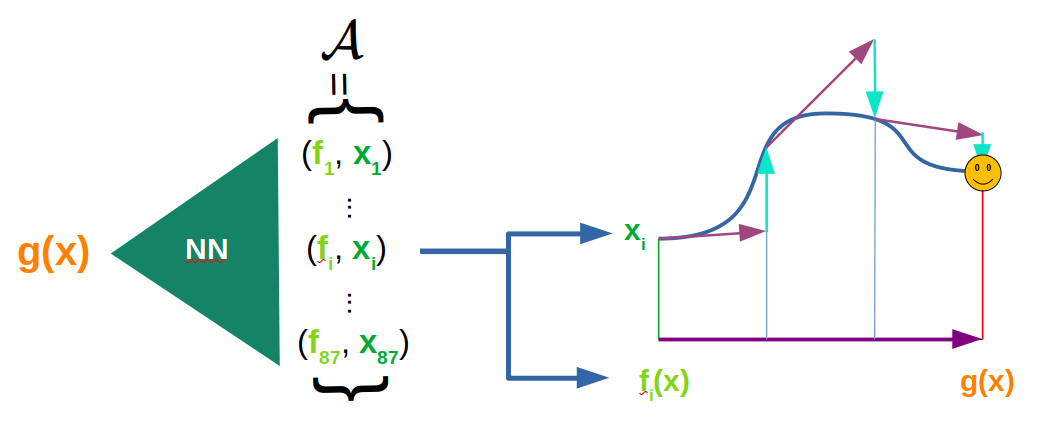
Geometry
Minimal Solvers
Solving polynomial systems that arise in solving the Computer Vision problems
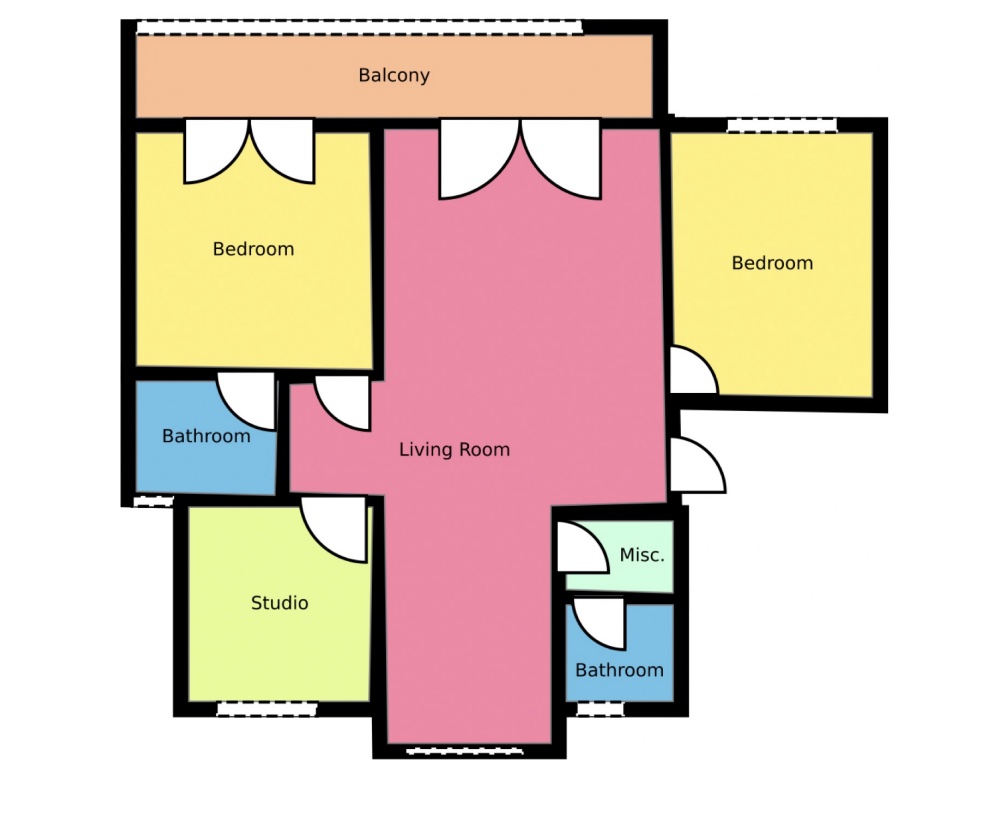
3D Scenes
Parameteric Scene Representations
Reconstruction of vectorized CAD models and parametric representations from 3D scans.